Cloudflare zásadne nepochopil, ako moderní AI asistenti fungujú, tvrdí Perplexity po tom, ako bola obvinená z obchádzania štandardov internetového prístupu. Spoločnosť Cloudflare zverejnila technickú analýzu, ktorá tvrdí, že automatizované boty napojené na Perplexity mali aj napriek výslovným zákazom pokračovať v načítavaní obsahu z tisícov webových stránok. Kľúčom v spore je protokol robots.txt, ktorý určuje, či a v akej miere môžu automatizované systémy interagovať s obsahom webu. O téme informuje portál ArsTechnica.
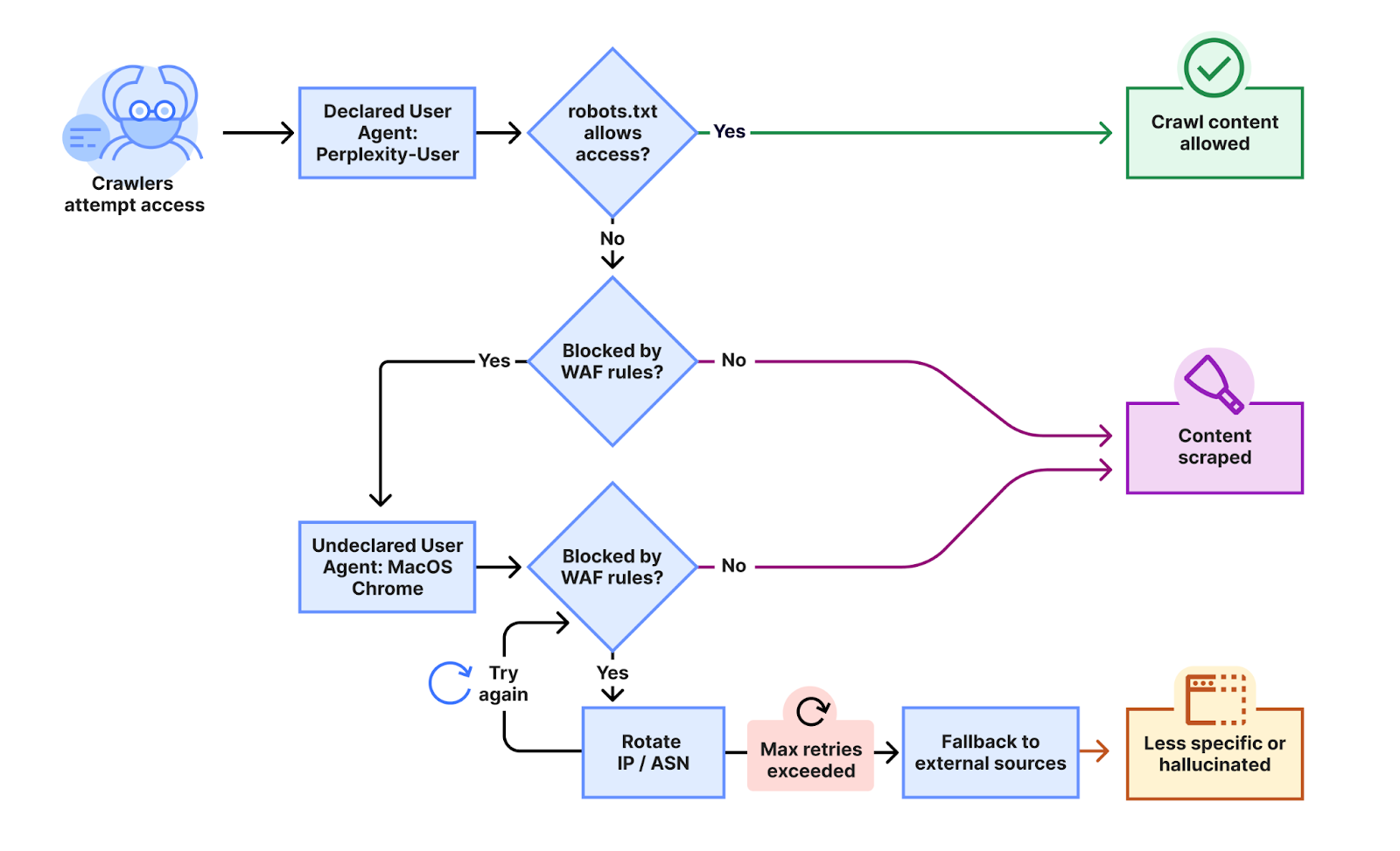
Cloudflare uvádza, že viacerí zákazníci nahlásili aktívne prístupy z neidentifikovaných zdrojov, aj napriek tomu, že Perplexity bolo výslovne blokované cez súbor robots.txt aj cez webové firewally. Následná analýza prevádzky ukázala, že ide o stealth crawling, teda techniku, pri ktorej prehľadávacie boty menia IP adresy, neidentifikujú sa korektne a zámerne obchádzajú obmedzenia.

Podľa Cloudflare sa tieto požiadavky objavili na viac než 10 000 doménach, pričom každý deň generovali milióny požiadaviek. Boty nepochádzali z verejne známeho rozsahu IP adries Perplexity a zároveň sa často prepájali cez rôzne autonómne systémy, čím sa znižovala možnosť ich detekcie. Cloudflare preto reagoval odstránením Perplexity zo zoznamu overených botov a upravil pravidlá pre správu automatizovanej prevádzky.
Cloudflare odkazuje na porušenie štandardizovaného protokolu robots.txt
Protokol robots.txt je súčasťou štandardného správania sa webových crawlerov už od roku 1994. V roku 2022 bol formálne schválený Internet Engineering Task Force ako uznávaný technický štandard. Webstránky týmto spôsobom určujú, ktoré sekcie ich obsahu nemajú byť indexované ani navštevované automatizovanými systémami. Hoci protokol nie je právne záväzný, ide o konsenzus, ktorý vytvára predvídateľné a férové prostredie medzi vlastníkmi obsahu a prevádzkovateľmi vyhľadávačov.
Cloudflare konštatuje, že boty musia byť transparentné, mať jasne definovanú funkciu a rešpektovať preferencie vlastníkov obsahu. Podľa spoločnosti Perplexity tieto zásady nespĺňa. K analýze Cloudflare zverejnil aj technický diagram, ktorý má ilustrovať, ako mala prebiehať činnosť skrytých prehľadávacích nástrojov napojených na Perplexity.
Perplexity AI reaguje na platforme X
Perplexity AI zverejnila oficiálne stanovisko, v ktorom zásadne odmieta obvinenia Cloudflare. V texte spoločnosť tvrdí, že Cloudflare nesprávne interpretoval sieťovú prevádzku a pripísal Perplexity požiadavky, ktoré nepochádzali z jej systémov. Namiesto toho išlo o prevádzku zo služby BrowserBase, externý cloudový prehliadač, ktorý Perplexity využíva len v špecifických prípadoch s nízkym objemom, menej než 450-tisíc požiadaviek denne.
Perplexity v podstate tvrdí, že „Cloudflare zásadne nepochopil, ako moderní AI asistenti fungujú,“ a uvádza, že Cloudflare mylne priradil tri až šesť miliónov požiadaviek nesprávnemu zdroju. Spoločnosť kritizuje, že Cloudflare nezverejnil metodológiu svojho sledovania a odmietla spolupracovať pri objasňovaní detailov. Taktiež označila zverejnený technický diagram za nepresný a nezodpovedajúci realite fungovania ich infraštruktúry.
— Perplexity (@perplexity_ai) August 5, 2025
Podľa Perplexity je táto situácia dôkazom, že systémy Cloudflare nedokážu spoľahlivo rozlíšiť medzi legitímnym AI asistentom a škodlivým scraperom. Perplexity sa taktiež nazdáva, že v dôsledku tejto neschopnosti Cloudflare nemá kompetenciu rozhodovať o tom, čo predstavuje legitímnu webovú prevádzku.